jhrep_public
Responses for July 20
A. I plan on creating a neural network that can guess population by a number of factors, such as land size, longitude/latitude, altitude, number of houses, etc.
Why: Population estimates aren’t inherently useful with places like the USA or the UK, since they already record this information. However, its possible that some areas either don’t have the resources to count population or simply don’t want to share that information with other countries. Hopefully, with this estimate, the model can provide population data that will further our global knowledge and, in turn, affect other estimates that are dependent upon population.
Plan: I will use satellite data and object detection to determine number of houses and additional data for the other features. Certain obstacles will be satellite image quality, finding satellite data, differentiating between houses and regular buildings, and house volume/height (specifically in regards to apartment buildings, as height is a relevant factor towards building population).
D. 1. We used RMSprop (or root mean squared prop) in this lab and, in the article “Understanding RMSprop,” we find that RMSprop can work much better (at reducing the loss function) than competing optimizers such as NAG, SGD, and Momentum.
D. 2. In the lab our loss function was binary cross entropy. With binary cross entropy, the loss is calculated by taking the negative log of the probabilities, so you have high losses for low probabilities (or confidence levels, I suppose) and low losses for high probabilities. Then, to calculate the binary cross entropy, you take the mean of these losses.
D. 3. Metrics just allow you to evaluate your model. In this lab we kept track of the accuracy, so we could tell how accurate the model was.
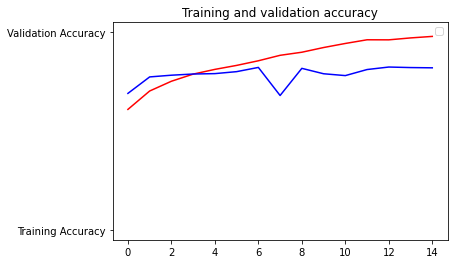
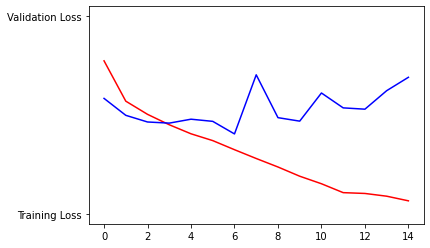
D. 4. Based on the graphs above, the model was doing alright until about epoch 7. Validation losses and accuracies are in blue, whereas training losses and accuracies are in red. You can see that the validation accuracy dipped at epoch 7 and never really caught up to the training accuracy. The discrepancy we see between the final validation accuracy and the final training accuracy is indicative of overfitting, which essentially means the model probably won’t perform well with new data.






 (This last one is solely for my own amusement)
(This last one is solely for my own amusement)
D. 5. The results are in the same order as the pictures:
- “dog1.jpeg is a dog”
- “dog2.jpg is a dog”
- “dog3.jpeg is a dog”
- “cat1.jpg is a cat”
- “cat2.jpg is a cat”
- “cat3.jpg is a dog”
- “cat4.jpg is a dog”
It got two wrong, but, to be fair, one wasn’t actually a cat, but a CGI cat/person from the movie Cats, although I really did think it would have gotten that right, given the similar features. The model performed pretty well (5/6 correct). I suppose a good way to improve the model would be to force the model to focus on specific features, like whiskers, for instance.